EvalMG25 @ COLING 2025
†National Center for High-performance Computing, Taiwan, §National Central University, Taiwan, ‡National Yang Ming Chiao Tung University, Taiwan, *National Taiwan University, Taiwan, ¶Institute of Information Science, Academia Sinica, Taiwan

We introduce TaiwanVQA, a novel visual question answering benchmark designed to evaluate vision-language models’ (VLMs) ability to recognize and reason about Taiwan-specific multimodal content. TaiwanVQA comprises 2,000 image-question pairs covering diverse topics relevant to Taiwanese culture and daily life. We categorize the questions into recognition and reasoning tasks, further sub-classifying reasoning questions based on the level of external knowledge required. We conduct extensive experiments on state-of-the-art VLMs, including GPT-4o, Llama-3.2, LLaVA, Qwen2-VL, and InternVL2 models. Our findings reveal significant limitations in current VLMs when handling culturally specific content. The performance gap widens between recognition tasks (top score 73.60%) and reasoning tasks (top score 49.80%), indicating challenges in cultural inference and contextual understanding. These results highlight the need for more culturally diverse training data and improved model architectures that can better integrate visual and textual information within specific cultural contexts. By providing TaiwanVQA, we aim to contribute to the development of more inclusive and culturally aware AI models, facilitating their deployment in diverse real-world settings. TaiwanVQA can be accessed on our GitHub page.
Multimodal vision-language models (VLMs) have achieved remarkable success in integrating visual and textual information. However, most benchmarks focus on general-domain knowledge and widely used languages, overlooking challenges posed by culturally specific content and languages like Traditional Chinese. Understanding and reasoning about nuanced local content is crucial for deploying AI systems worldwide.
To address this gap, we introduce TaiwanVQA, a benchmark evaluating VLMs’ abilities to handle Taiwan-specific content. TaiwanVQA includes questions about local cuisine, festivals, landmarks, and public signage—culturally and contextually rich elements of Taiwanese daily life.
TaiwanVQA consists of 1,000 images and 2,000 questions, evenly split into recognition and reasoning tasks. The reasoning tasks are further classified based on the complexity and external knowledge required, ensuring a multi-dimensional evaluation of model capabilities.
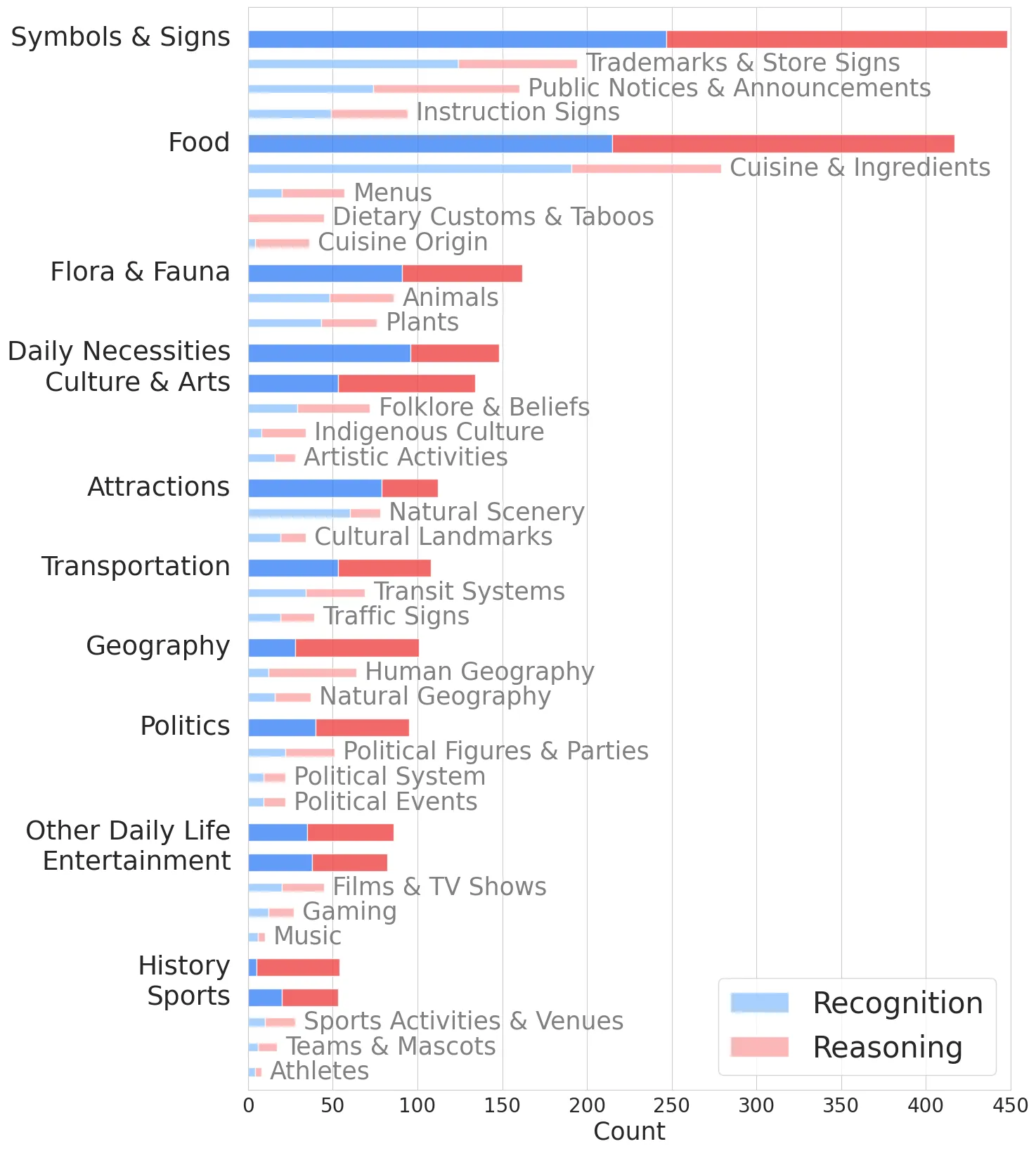
TaiwanVQA highlights the limitations of current VLMs when tackling culturally specific content, particularly in reasoning tasks that demand cultural inference. The benchmark can guide the development of more culturally aware and inclusive AI systems, ultimately improving their applicability in diverse real-world scenarios.
@inproceedings{taiwanvqa,
title={TaiwanVQA: A Visual Question Answering Benchmark for Taiwanese Daily Life},
author={Hsin-Yi Hsieh, Shang-Wei Liu, Chang-Chih Meng, Chien-Hua Chen, Shuo-Yueh Lin, Hung-Ju Lin, Hen-Hsen Huang, I-Chen Wu},
booktitle={EvalMG25 @ COLING 2025},
year={2024}
}